AI Model Optimization for a Fintech Virtual Advisor
100%
Critical issues resolved
95%
Faithfulness score achieved
70%
Reduction in QA time
Key Insights
Location
Germany
Project duration
6 weeks
Industry
Fintech
Technologies used
AWS Bedrock, Amazon Nova Pro, DeepEval, Amazon S3, PostgreSQL, AWS Lambda, API Gateway
Solutions
Introduction
A German B2B fintech company operating in the financial services partnered with Perfsys to improve the performance and reliability of its AWS-based AI assistant through AI model optimization. The client, a small team of under 10 employees, operates a well-known digital platform that aggregates verified customer reviews of financial advisors, banks, and insurers — helping consumers make informed financial decisions.
The client's vision was to build a reliable, knowledge-based AI assistant capable of answering complex user queries, referencing verified data, and maintaining context during long user interactions.
Background
The client had already implemented a serverless AWS architecture consisting of:
- Amazon Bedrock for AI inference
- Amazon S3 as a knowledge base repository
- AWS Lambda and API Gateway for orchestration
- A web UI for the frontend interface
Each AI "agent" represented a unique financial advisor persona sharing access to a centralized knowledge base stored in S3.
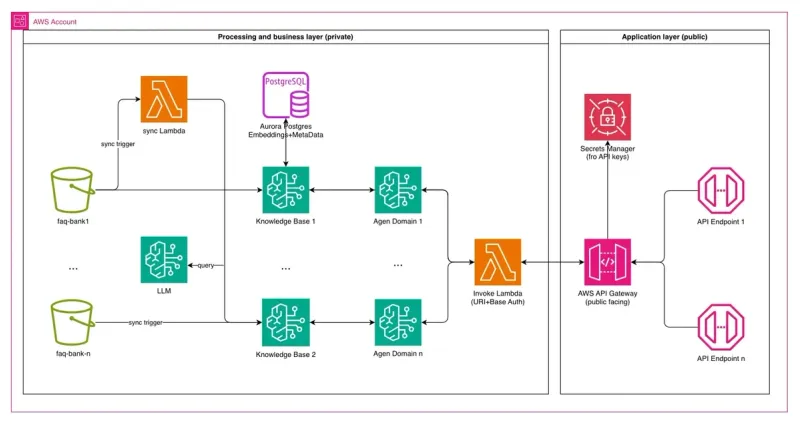
Despite this advanced setup, the agents were inconsistent, prone to hallucination, and often ignored the knowledge base, which compromised reliability. The client engaged us to quantify, diagnose, and systematically improve agent performance.
The Challenge
While the infrastructure was functional, the core challenge lay in AI quality and consistency:
- Agents forgot their personalities or initial instructions during extended conversations
- Context retention dropped significantly after 3–4 exchanges
- Agents produced hallucinated or incorrect answers, sometimes ignoring KB data
- No automated evaluation existed to track answer accuracy or reference validity
The client's main goal was clear:
"Ensure the AI agent provides accurate, reference-backed answers from the knowledge base, with measurable and repeatable quality metrics."
Our Approach to AI Model Optimization
Perfsys designed a three-phase improvement strategy combining evaluation automation, model experimentation, and AI model optimization at the prompt level.
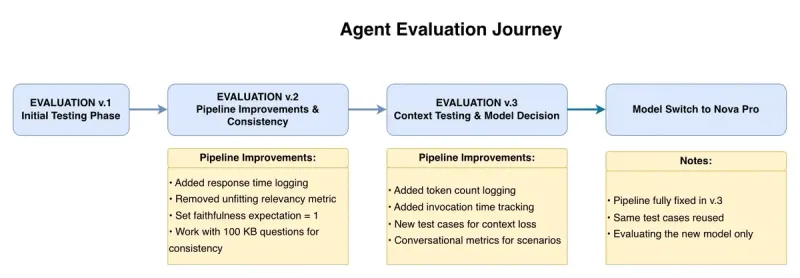
Baseline Evaluation Pipeline
We began by developing a custom Evaluation Pipeline based on the DeepEval framework . This pipeline allowed automatic testing of hundreds of AI interactions to measure:
- Faithfulness score (accuracy of KB reference usage)
- Response consistency
- Invocation time (latency)
The evaluation pipeline enabled:
- Running 500+ automated test cases across multiple sessions
- Establishing quantitative baselines for each tested model
- Reproducing real user interaction patterns
This became the foundation for systematic AI model optimization across all candidate models.
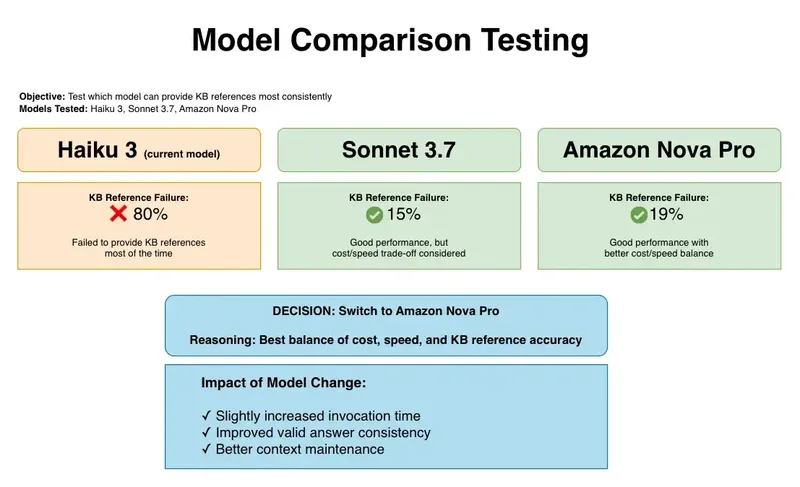
Model Comparison & AI Model Optimization Strategy
As part of our AI model optimization work, we tested three different models within AWS Bedrock:
The testing revealed that Claude 3 Haiku, the client's initial choice, failed to reference the KB correctly in 80% of cases.
While Sonnet 3.7 had better accuracy, Amazon Nova Pro offered optimal performance-to-cost ratio and superior consistency within Bedrock's ecosystem.
Post-Migration Issue Resolution
After migrating to Amazon Nova Pro , we identified and resolved several system-level issues:

Perfsys specializes in evaluation automation and AI model optimization on AWS. Contact us to discuss how we can help strengthen your AI workflows.
Results
Within six weeks, Perfsys successfully delivered a measurable improvement in AI performance and consistency through targeted AI model optimization.
Key Quantitative Outcomes
- 100% of critical issues resolved (language, fallback, KB consistency, and hallucination handling)
- Faithfulness score improved from 80% → 95%, ensuring nearly all answers are KB-based
- Evaluation automation reduced manual QA time by 70%, validating 500+ test cases per iteration
Impact Summary
- Valid answer consistency and reliability of KB usage significantly improved
- Invocation latency remained stable (~7 seconds average)
- Maintenance simplified through automated evaluation cycles
Conclusion & Next Steps
Through systematic testing, evaluation automation, and Bedrock-native AI model optimization, we helped the client transform a poorly performing AI assistant into a reliable, measurable, and scalable knowledge-based agent.
Next steps include:
- Expanding multilingual testing (DE, EN, FR)
- Integrating new agent personalities for domain-specific advisory roles
- Deploying the evaluation pipeline to monitor new model updates automatically
FAQ
AI model optimization is the process of improving an AI model so it delivers more accurate, consistent, and reliable results in real-world use. It includes testing different models, refining prompts, adjusting knowledge-base retrieval, and measuring accuracy and latency. In short, it helps the AI use the right information, avoid hallucinations, and perform efficiently in production.
Knowledge base accuracy ensures the AI agent provides answers grounded in verified information rather than hallucinating or guessing. High KB accuracy directly improves answer quality, consistency, and user trust — especially in industries like fintech.
AWS Bedrock provides a unified platform for comparing LLMs, integrating vector-based knowledge retrieval, and measuring performance metrics. This enables repeatable evaluations, reduced hallucinations, and optimized AI behavior without managing complex infrastructure.
The root cause was the model's limited faithfulness to the knowledge base. The initial Claude 3 Haiku model often generated answers from its own reasoning instead of referencing verified KB data stored in S3.
A faithfulness score measures how closely an AI's answer aligns with the knowledge base. A high score indicates the response is grounded in approved information rather than invented or hallucinated content.
Amazon Nova Pro provided the best balance of cost, speed, and accuracy for this use case. While Sonnet 3.7 showed slightly higher faithfulness, Nova Pro integrated more efficiently with AWS Bedrock and delivered faster, more consistent performance at a better cost-to-quality ratio.
Perfsys implemented a repeatable evaluation pipeline, running 500+ automated test cases to compare model performance before and after changes. This allowed us to track accuracy, latency, KB consistency, and overall improvements with quantifiable metrics.
AWS Bedrock – LLM hosting and knowledge base retrieval
DeepEval Framework – automated evaluation pipeline
Amazon S3 & PostgreSQL – vectorized knowledge-base storage
AWS Lambda + API Gateway – serverless orchestration

Eugene Orlovsky
CEO & Founder | Serverless architect with 10+ years of hands-on experience designing cloud-native architectures on AWS, backed by multiple AWS certifications. He is writing bridges deep technical expertise with real-world business strategy, covering topics from AWS best practices to scaling tech-driven organizations.
Recommended for You
AWS Experts, On-Demand
Need to move fast? Our cloud team is ready to scale, secure, and optimize your systems. Get serverless expertise, 24/7 support, and seamless CI/CD pipelines when you need it most.
Please accept cookies to load the booking widget.